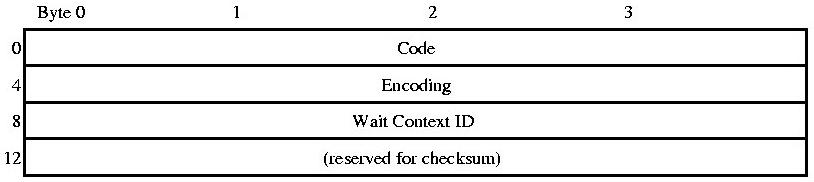
Fig 2.1 Message Header
Philip Shuman
June 1, 2000
Operating Systems Conference
California State University, San Luis Obispo
Dr. Elmo Keller
Distributed computing has been a research topic for years in the computer industry and education. There are many advantages to developing applications to run on distributed systems. Many workstations participating in a distributed computing group can offer their idle time to work on a problem at no extra cost to the organization. Dedicated inexpensive workstations can be grouped together to achieve super computer status at a fraction of the cost. Dedicated super computers can be clustered together to achieve greater computational speed. A number of important factors have slowed the growth of the distributed computing concept. Heterogenous computing environments and resistance to parallel programming have contributed to the slow start of distributed systems.
The Parallel Virtual Machine software is a project exploring distributed systems. The goal of its designers has been to help alleviate the burdens of heterogenous environments and facilitate the development of parallel software. The Parallel Virtual Machine libraries use standard networking protocols in interesting ways to connect these computers participating in these distributes environments.
The PVM is a set of tools and libraries that create a general-purpose, flexible framework for building parallel programs in the virtual machine that is emulated across heterogeneous systems. User libraries are provided to the programmer for communicating with the PVM system and other tasks in the virtual environment. Each user writes their application as a collection of cooperating tasks. PVM transparently handles all communication between tasks. The PVM message passing primitives are designed to work across heterogenous systems transparent to the programmer.
The Parallel Virtual Machine (PVM) project started at the United States Department of Energy's Oak Ridge National Laboratory in Tennessee as an experiment programming on Massively Parallel Processor (MPP) computers. Similarities between programming for distributed computer systems and Massively Parallel Processor machines made expanding PVM to support distributed computer systems and easy task. Programming paradigms for both systems can be based on message passing. Using an higher level abstract message passing system for process communication allows the processes to be oblivious to whether another process is running on the same computer or on another computer around the world communicating over a network. The PVM system allows a large number of MPP, SMP and uni-processor machines to appear as one large virtual machine to the applications running on top of the virtual machine[3].
PVM is distributed in source form from the various web sites of organizations contributing to the PVM project. Any user can build and install the PVM libraries and utilities in their home directory on any supported systems they have access to. Super user privileges are not required to build, install, or run PVM. Multiple users can run PVM on the same machine in disjoint virtual machines. A number of shell environment variables must be defined for PVM to work properly.
To limit the complexity of the PVM inter host communication, PVM relies on either rsh/rshd or ssh/sshd to start and stop instances of pvmd on remote systems. The user must setup rsh or ssh with the trusted host/trusted user information to allow pvmd remote access without being prompted for a password. This remote access allows the master pvmd to start and stop remote slave pvmd processes.
Each participating machine runs an instance of the PVM daemon (pvmd). The pvmd is responsible for managing any calls to PVM library functions by local processes, spawning any new tasks, and managing the communication between the pvmd processes on multiple hosts. The first instance of pvmd started is considered the master instance of pvmd and subsequently started pvmd processes are slaves. The PVM virtual machine can recover from the failure of any slave pvmd process, but the loss of the master is fatal to the virtual machine in the current implementation of PVM. This is better than the previous version of PVM which would crash if any pvmd prematurely disconnected. Another instance of the pvmd called the pvmd' also runs on each host. Any work that would lead to the pvmd blocking is passed to the pvmd' to perform.
Several utilities exist that allow a user to interact with the virtual machine. One such console utility is called pvm. It can be run from any computer participating in the virtual machine. The pvm console allows the user to manage the hosts participating in the virtual machine, manage the different tasks running in the virtual machine, manipulate environment variables, and view statistics. Other utilities provide similar functionality. Another such application is xpvm, a graphical version of pvm.
Each application is broken into smaller executable programs that can be executed in parallel. Each individual program must be available on every machine participating in the virtual machine. If different architectures are participating, binaries for each must be supplied. Each individual program running in the virtual machine is called a task. Tasks are very similar to a process in UNIX. Tasks have their own virtual memory spaces and a unique identifier number called a task identifier (tid). The tid is a unique per virtual machine 32 bit number. There are four fields in the tid: S, G, H and L. The 12 bit H field contains a host number relative to the virtual machine. Each host is assigned a unique H number. The maximum number of hosts is limited to 2H-1 (4095). The S bit is deprecated. The G bit is set to form a multicast address. The L bit is assigned by the local pvmd to create a unique tid for each local task. The tid for the pvmd on a host has the L bits set to 0.
PVM can be used as a framework to build any system that can be decomposed into smaller parallel tasks. PVM can be used to achieve super computer computational speeds with groups of smaller, less expensive computers. It is also used to coordinate process development and execution on Multi Parallel Processor computers. PVM is currently being used in many different areas including: aerodynamics, computer science, multi media, business, physics, math, simulations, and science. The wide spread use of PVM can be attributed to its scalability, ease of use, availability on over 60 platforms, and free distribution of the source code.
When programming for an MPP system, all processors are exactly the same. However when a virtual machine is created with many different types of systems, many factors need to be addresses. Issues involving architecture, data format, computational speed, machine loads, networks loads, and compiler differences can make achieving a reliable distributed application a difficult feat. Current distributed applications can be made available on desktop personal computers using Intel x86 or PowerPC architecture, high performance workstations from vendors like SUN and Silicone Graphics, shared-memory multi-processors, and vector super computers. If the programmer was responsible for taking these factors into account when developing a distributed application, development time would be near infinite. However using the PVM system, many of these issues are taken care of by the PVM libraries.
PVM uses the eXternal Data Representation (XDR) data encoding standard to transfer data between different tasks and from tasks to the PVM system. For example, XDR stores integers as big-endian and floating point numbers in IEEE format. The PVM system running on each host is responsible for encoding and decoding data from this format. For efficiency, the programmer can send raw data using PVM primitives without using XDR for homogenous data transfers.
Applications are generally developed with one program that acts as a loader and possibly a result processor. This program may either be spawned from the pvm console or started on a normal shell command line. Its job is to start up the other problem solving tasks with the appropriate part of the problem to solve. This uses the pvm_spawn function to create a new process in the virtual machine. The concept is similar to fork()/exec() or system() on a traditional uni-processor computer. The pvmd scheduler decides which actual host to start the process on.
The default scheduling built into the pvmd is very simple. It does not account for important factors like system load or network congestion. A resource manager can fill in this gap by monitoring the various operating systems that the virtual machine runs on top of and making more informed decisions about where new processes should be spawned.
PVM uses TCP, UDP, and UNIX-domain sockets to communicate. Other protocols were more appropriate for this type of application, these were chosen because of their wide spread support in operation systems. PVM has three types of connections: pvmd to pvmd, pvmd to task, and task to task.
Both pvmd and libpvm use the same type of message header. The Code field is a 4 byte integer specifying the message type. The Wait Context ID filed is used by the pvmd, resource manager, tasker and hoster tasks. The checksum field is not currently in use, but is reserved for future use. Messages can be fragmented and have a special fragment header.
Fig 2.1 Message Header
The PVM demons use UDP sockets to communicate. Due to the unreliable nature of UDP transport, we can loss packets, receive duplicates and out of sequence packets. So an acknowledgment and retry mechanism is built into the application layer that gets encapsulated in the standard UDP packet. The required overhead of TCP was considered to be too high considering every pvmd has a connection to many other pvmds. N hosts in the virtual machine require N(N-1)/2 TCP connections, but a single UDP connection can send to any number of remote UDP sockets.
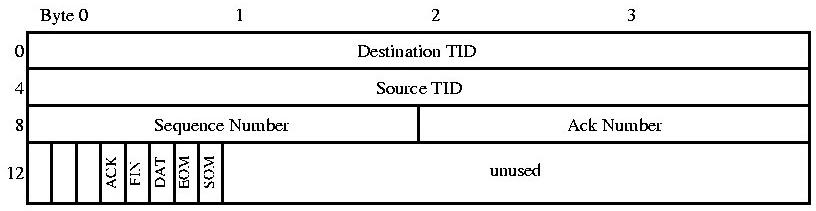
Fig 2.2 pvmd-pvmd
The pvmd-pvmd header contains many fields that are similar to those found in a TCP or other reliable transport protocols. FIN and ACK are similar to their TCP counterparts. SOM and EOM are set to used to delimit message boundaries of fragmented messages. The protocol driver uses a struct hostd to keep information about the connection and its state. (See Appendix)
A task talks to other tasks and pvmds through TCP sockets. A reliable transport layer is used to ensure delivery and order of the packets. The overhead of TCP is not an issue because of the 1 to 1 connections associated with pvmd to task and task to task communication. The data header is much simpler due to the reliable nature of TCP. SOM and EOM are still needed because TCP connections are streams with no natural breaks starting and ending individual messages. Sequence and acknowledgment fields are not needed in the application layer because the transport layer handles reliable delivery and ordering.
Fig 2.3 pvmd-task and task-task
The PVM library function pvm_mcast() can send a message to multiple destinations simultaneously. The current implementation routes these multicast messages to all pvmds to ensure that the loss of one pvmd would not prevent other pvmds from receiving the message. The pvmds packet routing layer must communicate with the user libraries to multicast the message. Multicast messages are sent by forming a multicast tid.
The PVM libraries and utilities simplify the process of distributing applications across multiple machines. The straight forward primitives make the learning curve and development time relatively short. The lower level nature of the PVM primitives is a deterrent to some programmers who want a higher level of abstraction in their distributed primitives. Linda[2] and CORBA are other distributed computing systems that bridge this gap.
While there are still many challenges to programming in heterogenous distributed environments, PVM has started to address many of the issues. The job of the programmer has been simplified tremendously. Issues such as data representation across heterogeneous platforms, network transport, and task management are handled by the PVM system for the user. While distributed computing is not in every home and business today, it has found a place in many areas of computational research and industry. As the tools become more streamlined, we will see distributed computing grow in to more and more fields.
Definitive Resource:
Geist , Beguelin, Dongarra, Jiang, Manchek, Sunderam, PVM: Parallel Virtual Machine. 1994.
MIT Press.
Blackford, A. Cleary, A. Petitet, R.C. Whaley, J. Demmel, I. Dhillon, H. Ren, K. Stanley, J. Dongarra and S. Hammarling, Practical Experience in the Numerical Dangers of Heterogeneous Computing. ACM Transactions on Mathematical Software. June 1997 v23 n2 p133(15)
Carriero, Nicholas and Gelernter,David, "Linda in Context", Communications of the ACM, Vol. 32, No. 4, April 1989, pages 444-458.
Schmidt, D., Mohamed, F., Lessons Learned: Building Reusable OO Frameworks for Distributed Doftware. Communications of the ACM v40 n10 p85(3) 1997.
Talia, Domenico, Parallel Computation Still Not Ready for the Mainstream. Communications of the ACM July 1997 v40 n7 p98(2)
/* Host descriptor */
struct hostd {
int hd_ref; /* num refs to this struct */
int hd_hostpart; /* host tid base */
char *hd_name; /* name */
char *hd_arch; /* cpu arch class */
char *hd_login; /* loginname [used master only] */
char *hd_dpath; /* daemon executable */
char *hd_epath; /* task exec search path */
char *hd_bpath; /* debugger executable */
char *hd_wdir; /* pvmd working dir */
char *hd_sopts; /* hoster options */
int hd_flag;
int hd_dsig; /* data signature */
int hd_err; /* error code */
int hd_mtu; /* max snd/rcv length */
/* struct sockaddr_in hd_sad; /^ UDP address/port */
int hd_rxseq; /* expected next seq num from host */
int hd_txseq; /* next tx seq num to host */
/* struct pkt *hd_txq; /^ not-yet-sent packet queue to host*/
/* struct pkt *hd_opq; /^ outstanding packets to host */
int hd_nop; /* length of opq */
/* struct pkt *hd_rxq; /^ packet reordering queue from host*/
/* struct pmsg *hd_rxm; /^ to-us msg reassembly from host */
/* struct timeval hd_rtt; /^ estd round-trip time to host */
int hd_speed; /* cpu relative speed */
/* struct mca *hd_mcas; /^ from-host mca cache */
char *hd_aname; /* name to use for network address */
};
/* Host table */
struct htab {
int ht_serial; /* serial number */
int ht_last; /* highest entry */
int ht_cnt; /* number of entries (not incl [0]) */
int ht_master; /* master host */
int ht_cons; /* console host */
int ht_local; /* this host */
int ht_narch; /* count of different data reps */
struct hostd **ht_hosts; /* hosts */
};
/* descriptor for a message */
struct pmsg {
struct pmsg *m_link; /* chain or 0 */
struct pmsg *m_rlink;
struct encvec *m_codef; /* data encoders/decoders */
struct frag *m_frag; /* master frag or 0 if we're list head */
struct frag *m_cfrag; /* pack/unpack position */
int m_ref; /* refcount */
int m_mid; /* message id */
int m_len; /* total body length */
int m_ctx; /* communication context */
int m_tag; /* type tag */
int m_wid; /* wait id */
int m_src; /* src address */
int m_dst; /* dst address */
int m_enc; /* encoding signature */
int m_flag;
int m_cpos; /* pack/unpack position */
int m_crc; /* CRC from header */
XDR m_xdr;
};
static char rcsid[] =
"$Id: hello.c,v 1.2 1997/07/09 13:24:44 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include
#include "pvm3.h"
main()
{
int cc, tid;
char buf[100];
printf("i'm t%x\n", pvm_mytid());
cc = pvm_spawn("hello_other", (char**)0, 0, "", 1, &tid);
if (cc == 1) {
cc = pvm_recv(-1, -1);
pvm_bufinfo(cc, (int*)0, (int*)0, &tid);
pvm_upkstr(buf);
printf("from t%x: %s\n", tid, buf);
} else
printf("can't start hello_other\n");
pvm_exit();
exit(0);
}
static char rcsid[] =
"$Id: hello_other.c,v 1.2 1997/07/09 13:24:45 pvmsrc Exp $";
/*
* PVM version 3.4: Parallel Virtual Machine System
* University of Tennessee, Knoxville TN.
* Oak Ridge National Laboratory, Oak Ridge TN.
* Emory University, Atlanta GA.
* Authors: J. J. Dongarra, G. E. Fagg, M. Fischer
* G. A. Geist, J. A. Kohl, R. J. Manchek, P. Mucci,
* P. M. Papadopoulos, S. L. Scott, and V. S. Sunderam
* (C) 1997 All Rights Reserved
*
* NOTICE
*
* Permission to use, copy, modify, and distribute this software and
* its documentation for any purpose and without fee is hereby granted
* provided that the above copyright notice appear in all copies and
* that both the copyright notice and this permission notice appear in
* supporting documentation.
*
* Neither the Institutions (Emory University, Oak Ridge National
* Laboratory, and University of Tennessee) nor the Authors make any
* representations about the suitability of this software for any
* purpose. This software is provided ``as is'' without express or
* implied warranty.
*
* PVM version 3 was funded in part by the U.S. Department of Energy,
* the National Science Foundation and the State of Tennessee.
*/
#include "pvm3.h"
main()
{
int ptid;
char buf[100];
ptid = pvm_parent();
strcpy(buf, "hello, world from ");
gethostname(buf + strlen(buf), 64);
pvm_initsend(PvmDataDefault);
pvm_pkstr(buf);
pvm_send(ptid, 1);
pvm_exit();
exit(0);
}
Philip Shuman